Automated Score Tuning for SpamAssassin
2006/01/18
During the creation of an institute-wide spamfilter system based on SpamAssassin we have collected a set of 77,286 ham and spam mails from
eight users, developed our own training methods and evaluated them against commercial and free spam filtering systems, including Symantec BrightMail 6. A more recent report puts the work in larger context, adds new empirical results and proposes a convenient approach for mail data collection.
Scripts to train SpamAssassin
One of the outcomes of this research was a way to adapt SpamAssassin to a specific
mail collection. Contrary to sa-learn, which only trains the NaiveBayes model, SA-Train.pl additionally learns a set of score values via linear SVM. I found out
early that a single score value set is not sufficient for all applications. The approach outlined here is similar to SA-Train with training methodology simple.
- SA-Collect.pl: collects a set of most recent mails
from a mail archive. Only folders in mbox format, or maildirs (provided each mail begins with ^From\ ) are currently supported. If you use Mozilla or
mutt/pine/elm you should be fine... even Thunderbird might work.
- SA-Train.pl: Main learner script. Computes a CV
on input data, or just learns the full model (default). In the latter case, user_prefs and
bayes_* files are to be found in the current directory, and just need to be
copied to the right place. Don't forget to adapt bayes_path (in user_prefs).
If it is not set correctly, you will get no BAYES_* tests in the mail header, and performance will suffer (except for -S).
SA-Train.pl uses Algorithm::SVM V0.12 instead of the perl-port of WEKA's SMO
which I used before. It should be around three times faster. There have also
been optimizations concerning memory usage which has been reduced about
twentyfold. Until the time that Algorithm::SVM V0.12 appears at CPAN, you can download the
latest version here (source code).
Bugs, comments and extension requests are welcome. If you use this for research purposes, please cite one of the papers - preferable the IDA Journal paper.
Performance
Since the latest version, SA-Train can also use simplified training procedures
-S and -B, which work as follows: -S ignores the NaiveBayes model and just learns
the linear SVM, which is somewhat similar to the process for obtaining the
default scores for each new version of SpamAssassin; -B outputs static weights
for the BAYES_* tests and ignores all other tests (i.e. sets their score to 0),
which essentially reduces to a pure NaiveBayes learner (similar to
SpamBayes).
Based on our sample of 77286 mails with a spam/ham ratio of roughly 1, and using
a five-fold crossvalidation, these are the results for the main three settings
-S, -B and the default one (neither -B nor -S specified). All values in percent (i.e. multiplied by 100)
| (default) | -S | -B |
| Ham error (FP rate) | 0.420±0.047 | 1.495±0.171 | 0.089±0.015 |
| Spam error (FN rate) | 0.423±0.030 | 3.550±0.232 | 2.549±0.276 |
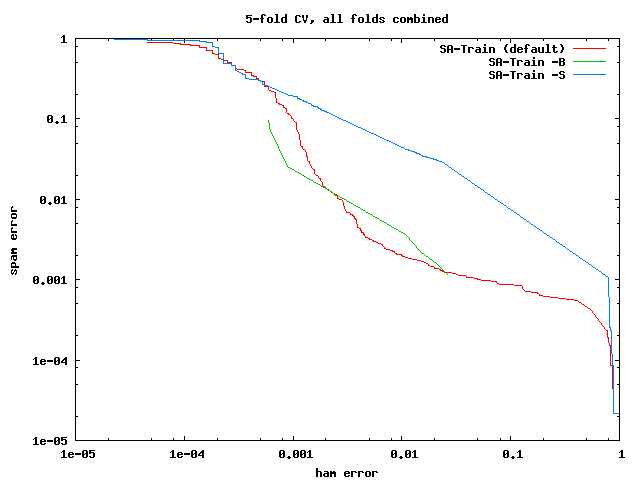
Another way to look at the performance is with ROC curves. In this case, we have
plotted ham vs. spam error at all possible thresholds. This needs a logarithmic
scale, otherwise the differences between the three settings would be too small.
This is what you can see on the left. As you can see, -B and the default setting
are rather close. Since -B is the fastest, I would suggest to try it first.
The default threshold (required_hits) of 5 reduces ham error at
the cost of increased spam error. If you want similar performance as the
default setting, change the threshold to 2.
You could also try the default setting with different complexity parameters
for the SVM (i.e. the -c parameter), which you should vary systematically. Using
different thresholds for SVM output - as we did here - is not really sensible,
as it will lose the optimality of the underlying optimization problem.
What works worst is not using the bayesian model, which is what -S does.
This is reasonably similar to what the SpamAssassin developers do to compute
the default scores, which also give very bad performance on this sample.
Mail data collection
How mails should be collected at an institute
- i.e. generating a model for a large(r) number of users.
- empty all files where SpamAssassin puts automatically
recognized spam mails (possibly backup first, so no
misclassified mails get lost)
- ask all institute members to collect spam that comes
through, into separate mailboxes (e.g. spam)
- After 1-2 weeks, put all SA-recognized mails and members-
collected mails into one mailbox per user. Check this
mailbox extensively for misclassified mails!
- Use SA-Collect.pl to get the same number of ham mails
from non-spam mailboxes. This ensures a Spam-to-Ham ratio of
1.0. Again, check this mailbox extensively for misclassifications!
- Using SA-Train.pl, train via -x 2, 5 or 10 - depending on how long
you can wait. ;-) Afterwards, full training (default, -x 0/1)
will give user_prefs and bayes_* files for SpamAssassin.
- You will need at least 1000 mails - the more, the better.
SA-Train at OFAI (www.ofai.at) uses around 50,000 mails and remains
stable for 6-12 months.
This collection procedure gives excellent results, is less costly that
incremental training (no more checking tens of thousands of spam mails
for the elusive false positive) and the filter should work from
day one with the error rates estimated via CV. Humans are of course not
perfect at this task: error estimates range from 0.25% to 1%, so everything
within this range is competitive.
Datasets
For confidentiality reasons, I cannot give away my full mailbox
collection. However, I have chosen to contribute a small part of my
personal emails in a reasonably safe form - as word vector of their
contents, as results from SpamAssassin rule sets, and actual full sender email
addresses (see downloads)
2005/12/31
 Research, design and development of a SpamAssassin-based spam filter system (sampling methodology, training methodology, evaluation), initially seven test users, prepared for institute-wide deployment; involved in many locally and EU-funded research projects.
Research, design and development of a SpamAssassin-based spam filter system (sampling methodology, training methodology, evaluation), initially seven test users, prepared for institute-wide deployment; involved in many locally and EU-funded research projects.
2007/01/01
Seewald A.K.: An Evaluation of Naive Bayes Variants in Content-Based Learning for Spam Filtering. Intelligent Data Analysis 11(5), pp. 497-524, 2007.
2005/01/01
Seewald A.K.: A Close Look at Current Approaches in Spam Filtering. Technical Report, Austrian Research Institute for Artificial Intelligence, Vienna, TR-2005-04, 2005.
2004/08/01
Seewald A.K.: Combining Bayesian and Rule Score Learning: Automated Tuning for SpamAssassin. Technical Report, Austrian Research Institute for Artificial Intelligence, Vienna, TR-2004-11, 2004.